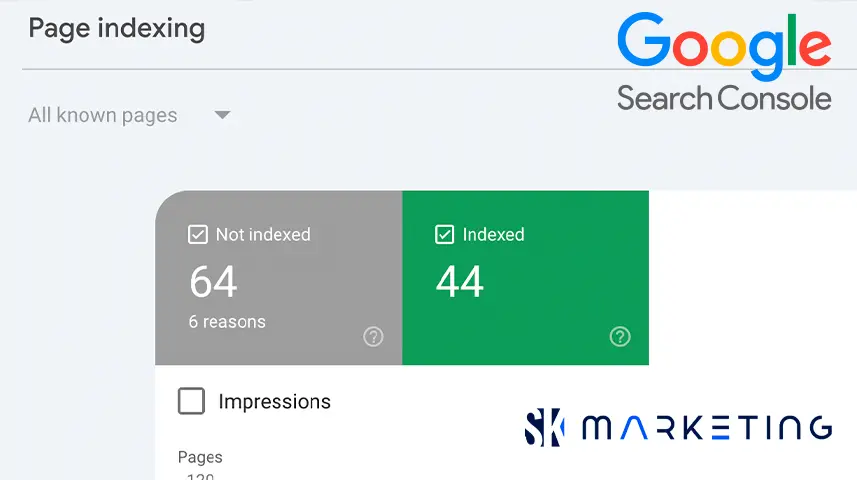
Explaining Google Search Console messages
These Google Search Console notices can be confusing, especially if you’re not sure you “intentionally” created such situations. Let’s unpack each reason why pages may not be indexed and what to do.
Core principle: Google wants to index only unique, most relevant content. If there are multiple versions of the same page or the page redirects, Google sees no need to index each version to avoid duplication.
Key point: only one version of content is indexed; redirects and canonicals are normal signals if they point to the right URL.
1. “Page with redirect”
What it means: When Googlebot visits a URL, it gets a signal (e.g., HTTP 301 or 302) telling it to go to another URL. Google doesn’t index the source URL because the “real” content is at the destination.
Why it happens (intentional vs. unintentional):
Redirect checklist: chain no longer than 1–2 hops, final URL indexable, internal links go straight to the final page.
Intentional:
- URL structure change: You changed a page URL and the old one redirects to the new one. Correct and necessary to keep link equity.
- HTTP to HTTPS: All traffic is redirected to HTTPS. Standard security practice.
- www ↔ non-www: You chose one canonical host (e.g.,
site.cominstead ofwww.site.com) and set a redirect. - Merging pages: Two old pages are merged into one new page with redirects from the old ones.
- Removing duplicates: e.g.,
site.com/index.htmlredirected tosite.com/.
Unintentional (potential issue):
- Redirect misconfigurations: Loops, long chains, or redirects to wrong URLs.
- Plugins/CMS: Some plugins or CMS settings may auto-create redirects without you noticing (e.g., after title changes).
- Internal links: Old redirected URLs still linked internally. Not fatal, but wastes crawl budget—better to update.
If it’s a “problem”:
- Check the URL: Open it. Where does it land? Is that expected?
- Check the redirect chain: Use tools like
httpstatus.io. Make sure the chain is short (ideally 1–2 hops) and error-free. - Update internal links: Point them directly to the destination URL to improve crawl efficiency and speed.
- Ensure the destination indexes: If the redirect is intentional, the final URL should be indexable and appear in Google.
Takeaway for “Page with redirect”: Most of the time it’s normal and desired. Google simply tells you it does not index the source URL but indexes the destination URL. It’s an issue only if the redirect goes somewhere wrong or the destination isn’t indexed.
2. “Duplicate, Google chose different canonical than user”
What it means: Google found several pages with very similar or identical content. You either set one as canonical with rel="canonical", or Google itself picked one as canonical. In this case Google decided the page shown in the report is not canonical and will not be indexed.
This specific notice: You declared one canonical, but Google’s algorithms picked another as the better canonical. That’s the one Google indexes.
Why it happens (intentional vs. unintentional):
Canonical rules of thumb: one main URL per set; self-canonical in the <head>; make variants unique if they should index separately.
Intentional (normal cases):
- Filters and sorting: Base page
/productsvs. variants/products?color=redor/products?sort=price_asc. Canonical to/productsis correct. - Pagination:
/category/page/1/,/category/page/2/, etc.; sometimes canonical to page 1. - UTM/session params: Tracking URLs (e.g.,
/article?utm_source=email) point canonical to the clean article. - Different URL forms:
site.com/page/vs.site.com/page/index.html; you pick one canonical. - Accidental duplicates: Same article under two URLs, later fixed with
rel="canonical".
Unintentional (problem cases):
- Technical duplicates: CMS creates variants (e.g.,
/category/product-nameand/product-name). - Wrong CMS/plugin setup: SEO plugin sets an incorrect canonical or isn’t configured.
- Trailing slashes inconsistency:
/pagevs./page/treated as different. Keep one format. - HTTP/HTTPS, www/non-www: If both are accessible and canonical is wrong, Google may see duplicates.
- Copied content: Content taken from another site; Google recognizes the original source.
If it’s a “problem”:
- Check the URL and content: What page is it? Does it really duplicate another?
- Check
rel="canonical": In page source (<head>) find<link rel="canonical" href="...">.- Where does
hrefpoint? Is that the URL you want as canonical? - Is it self-referencing? If
hrefmatches the current URL, the page considers itself canonical.
- Where does
- Compare “suspicious” pages:
- Compare content of the non-indexed page with the one Google chose as canonical. Are they very similar?
- If they must differ but Google sees duplicates, unique the content or revisit site structure.
- If they should match and canonical is correct, this is normal: Google indexes only one.
Example scenario “Duplicate, Google chose different canonical than user”:
- You have
example.com/product-a. - Also
example.com/product-a?sort=new(same product, sorted). - On
product-a?sort=newyou setrel="canonical"toexample.com/product-a. - Google prefers
example.com/product-aas cleaner and ignores the parameter variant. - Report shows
example.com/product-a?sort=newas “Duplicate, Google chose different canonical than user”.
What to do:
- If Google picked the right canonical: Do nothing—Google agrees with your logic.
- If Google picked the wrong one:
- Recheck
rel="canonical": ensure it points to the truly correct page. - Unique content: if Google keeps choosing another page, your “non-canonical” pages may differ too much or not be unique enough.
- Use 301 redirects: if the “duplicate” should never be accessed (e.g., old version), redirect to the canonical. Stronger signal than canonical.
- Recheck
Takeaway for both:
- “Page with redirect”: usually normal. Ensure it points to the right destination and that destination indexes.
- “Page variant with canonical”: also often normal when you manage duplicates. Issue only if Google picks the wrong page or marks a truly unique page as duplicate.
Your task
- Don’t panic. These notices aren’t always problems.
- Open Google Search Console → “Indexing → Pages”.
- Review example URLs for each category.
- For each URL:
- Use GSC “URL Inspection”.
- Check where the redirect goes, or which page is selected as canonical.
- Decide:
- Is this expected? (Old URL to new one, filtered page to canonical product) → Do nothing.
- Is this an error? (Redirect to 404, wrong canonical, two different pages marked duplicates) → Fix it.
Google simply informs you about its indexing process. Often it means it handled duplicates and redirects successfully, and you don’t need to act. The key is to ensure important pages index and duplicates or old URLs are handled correctly.
Summary
- Redirect: usually fine if the destination is indexed and the chain is clean.
- Canonical: fine when the right original is chosen; an issue if Google picks the wrong one or the page is truly unique.
- Actions: check canonicals and redirects, refresh internal links, reduce duplicates, use 301 where needed.
- Final check: key pages index; duplicates and old addresses are redirected or closed correctly.
Tags: